CPU异常
概述
异常表示当前指令执行时碰到了问题。例如,如果当前指令试图除0,则CPU发出异常。当发生异常时,CPU会中断其当前工作并立即调用特定的异常处理函数,具体取决于异常类型。
在x86上有大约20种不同的CPU异常类型。最重要的是:
- 页面错误:非法内存访问发生页面错误。例如,如果当前指令尝试从未映射的页面读取或尝试写入只读页面。
- 无效操作码:当前指令无效时会发生此异常,例如,当我们尝试在不支持它们的旧CPU上使用较新的SSE指令时。
- 通用保护错误:这是可能的发生原因最多的异常。它发生在各种特权级不正确的访问时,例如尝试在用户级代码中执行特权指令或在配置寄存器中写入保留字段。
- 双重故障:发生异常时,CPU尝试调用相应的处理函数。如果在调用异常处理程序时发生另一个异常,则CPU会引发双重故障异常。当没有为异常注册处理函数时,也会发生此异常。
- 三重故障:如果在CPU尝试调用双重故障处理程序功能时发生异常,则会发出致命的三重故障。我们无法捕获或处理三重故障。大多数处理器通过重置自身并重新启动操作系统来做出反应。
完整的异常列表,请见 OSDev wiki。
中断描述符表
为了捕获和处理异常,我们必须设置一个所谓的中断描述符表(IDT)。在此表中,我们可以为每个CPU异常指定处理函数。硬件直接使用此表,因此我们需要遵循预定义的格式。每个条目必须具有以下16字节结构:
| 类型 | 名称 | 介绍 |
|---|---|---|
| u16 | 函数指针 [0:15] | 中断处理函数的 [0:15] 位。 |
| u16 | GDT选择子 | 全局描述符表中的代码段选择子。 |
| u16 | 选项 | (见下) |
| u16 | 函数指针 [16:31] | 中断处理函数的 [16:31] 位。 |
| u32 | 函数指针 [32:63] | 中断处理函数的 [32:63] 位。 |
| u32 | 保留 |
其中可选字段具有以下格式:
| 位 | 名称 | 介绍 |
|---|---|---|
| 0-2 | 中断堆栈表索引 | 0: 不更换任务堆栈, 1-7: 当这个处理函数被调用时会切换到中断堆栈表中的第n个栈。 |
| 3-7 | 保留 | |
| 8 | 0: 中断门,1: 陷入门 | 若这个位是0,处理函数被调用时会禁止中断。 |
| 9-11 | 全1 | |
| 12 | 0 | |
| 13‑14 | 描述符特权集l(DPL) | 调用这个处理函数的最低特权集。 |
| 15 | 存在 | 标记这个表项是否存在 |
每个异常都有一个预定义的IDT索引。例如,无效操作码异常表索引为6,页面错误异常表索引为14。因此,硬件可以为每个异常自动加载相应的IDT条目。 OSDev wiki 中的异常表在“Vector nr.”一列中列出了所有异常的IDT索引。
发生异常时,CPU大致执行了以下操作:
将一些寄存器的值压入堆栈,包括指令指针和RFLAGS寄存器。 (我们将在本文后面使用这些值。)
从中断描述符表(IDT)中读取相应的条目。例如,CPU发生页面错误时会读取第14个条目。
检查条目是否存在。如果没有,则引发双重故障。
如果条目是中断门(未设置位40),则禁用硬件中断。
将指定的GDT选择器加载到CS段中。
跳转到指定的处理函数。
暂时不要担心步骤4和5,我们将在以后的帖子中了解全局描述符表和硬件中断。
IDT类型
我们将使用x86_64 crate的InterruptDescriptorTable结构体,而不是创建我们自己的IDT类型,如下所示:
1 |
|
这些字段的类型为 idt::Entry<F>,它是一个表示IDT条目字段的结构(参见上表)。 类型参数F定义了预期的处理函数类型。 我们看到一些条目需要HandlerFunc,而一些条目需要HandlerFuncWithErrCode。 页面错误甚至有自己的特殊类型:PageFaultHandlerFunc。
我们先来看看HandlerFunc类型:
1 | type HandlerFunc = extern "x86-interrupt" fn(_: &mut ExceptionStackFrame); |
它是extern "x86-interrupt" fn类型的类型别名。 extern关键字定义了一个具有外部调用约定的函数,通常用于与C代码(extern "C" fn)进行通信。 但是什么是x86-interrupt调用约定?
中断调用约定
异常与函数调用非常相似:CPU跳转到被调用函数的第一条指令并执行它。之后,CPU跳转到返回地址并继续执行父函数。
但是,异常和函数调用之间存在一个主要区别:函数调用由编译器插入的call指令自动调用,而异常可能在任何指令处发生。为了理解这种差异的后果,我们需要更详细地检查函数调用。
调用约定指定函数调用的详细信息。例如,它们指定放置函数参数的位置(例如,在寄存器中或堆栈上)以及返回结果的方式。在 x86_64 Linux 上,以下规则适用于C函数(在System V ABI中指定):
- 前六个整数参数在寄存器
rdi,rsi,rdx,rcx,r8,r9中传递 - 其他参数在堆栈上传递
- 结果放置在
rax和rdx中返回
请注意,Rust不遵循C ABI(实际上,现在甚至还没有Rust ABI这种东西),因此这些规则仅适用于声明为extern“C”fn的函数。
保留和临时寄存器
调用约定将寄存器分为两部分:保留寄存器和临时寄存器。
保留寄存器的值必须在函数调用前后不变。因此,只有在返回之前恢复其原始值时,才能允许被调用函数(“callee”)使用这些寄存器。因此,这些寄存器称为“callee-saved”。一种常见的模式是在函数开始时将这些寄存器保存到堆栈中,并在返回之前将它们恢复。
相反,允许被调用函数无限制地覆盖临时寄存器。如果调用者想要在函数调用中保留临时寄存器的值,则需要在函数调用之前备份和恢复它(例如,通过将其推送到堆栈)。因此,临时寄存器将被(“caller”)保存,被称为“caller-saved”。
在x86_64上,C调用约定指定以下保留和临时寄存器:
| 保留寄存器 | 临时寄存器 |
|---|---|
rbp, rbx, rsp, r12, r13, r14, r15 |
rax, rcx, rdx, rsi, rdi, r8, r9, r10, r11 |
| callee-saved | caller-saved |
编译器知道这些规则,因此它会生成相应的代码。例如,大多数函数以push rbp开头,它把rbp压入栈来备份(因为它是callee-saved的寄存器)。
保留所有寄存器
与函数调用相反,任何指令都可能发生异常。在大多数情况下,我们甚至不知道在编译时生成的代码是否会导致异常。例如,编译器无法知道指令是否导致堆栈溢出或页面错误。
由于我们不知道何时发生异常,因此我们之前无法备份任何寄存器。这意味着我们不能使用依赖于caller-saved的寄存器的调用约定来处理异常处理程序。相反,我们的调用约定要保留所有寄存器。 x86中断调用约定就是这样一种调用约定,因此它保证所有寄存器值在函数返回时恢复为其原始值。
异常堆栈帧
在正常的函数调用(使用call指令)时,CPU在跳转到目标函数之前压入返回地址。在函数返回(使用ret指令)时,CPU弹出此返回地址并跳转到它。所以普通函数调用的堆栈帧如下所示:

但是,对于异常和中断处理程序,将返回地址压入堆栈中是不够的,因为中断处理程序通常在不同的上下文中运行(堆栈指针,CPU标志等)。而是在发生中断时CPU执行以下步骤:
- 对齐堆栈指针:任何指令都可能发生中断,因此堆栈指针也可以是任何值。但是,某些CPU指令(例如某些SSE指令)要求堆栈指针在16字节边界上对齐,因此CPU在中断之后立即执行这种对齐。
- 切换堆栈(在某些情况下):当CPU权限级别更改时发生堆栈切换,例如在用户模式程序中发生CPU异常时。还可以使用所谓的中断堆栈表(在下一篇文章中描述)为特定中断配置堆栈切换。
- 旧堆栈指针压栈:CPU在中断发生时(对齐之前)将堆栈指针(
rsp)和堆栈段(ss)寄存器的值压栈。这使得从中断处理程序返回时可以恢复原始堆栈指针。 - 将
RFLAGS寄存器压栈并更新其值:RFLAGS寄存器包含各种控制和状态位。在进入中断处理时,CPU会更改一些位并向堆栈中压入旧值。 - 指令指针压栈:在跳转到中断处理程序功能之前,CPU按下指令指针(
rip)和代码段(cs)。这与正常函数调用的返回地址的压栈相当。 - 错误代码压栈(对于某些异常):对于某些特定异常(例如页面错误),CPU会将错误代码压栈,该代码描述异常的原因。
- 调用中断处理程序:CPU从IDT中的相应字段读取中断处理程序函数的地址和段描述符。然后通过将值加载到
rip和cs寄存器中来调用此处理程序。
所以异常堆栈帧如下所示:

在x86_64 crate 中,异常堆栈帧由ExceptionStackFrame结构表示。它作为&mut传递给中断处理程序,可用于检索有关异常原因的其他信息。该结构不包含错误代码字段,因为只有少数异常会推送错误代码。这些异常使用单独的HandlerFuncWithErrCode函数类型,该函数类型具有额外的error_code参数。
请注意,LLVM中当前存在一个错误,导致错误的错误代码参数。该问题的原因已为人所知,并有人正在着手解决。
幕后
x86-interrupt调用约定是一个强大的抽象,几乎隐藏了异常处理过程的所有混乱细节。然而,有时知道幕布背后发生了什么是有用的。以下是x86中断调用约定要处理的事项的简短概述:
- 检索参数:大多数调用约定都希望参数在寄存器中传递。这对于异常处理程序是不可能的,因为在将它们备份到堆栈之前我们不能覆盖任何寄存器值。相反,
x86-interrupt调用约定已经知道参数已经位于特定偏移量的堆栈上。 - 使用
iretq返回:由于异常堆栈帧与正常函数调用的堆栈帧完全不同,因此我们无法通过正常的ret指令从处理程序函数返回。相反,必须使用iretq指令。 - 处理错误代码:错误代码在某些异常发生时被压入堆栈,使事情变得更加复杂。它会更改堆栈对齐的方式(请参阅下一点),并且需要在返回之前弹出堆栈。
x86-interrupt调用约定处理所有复杂性。但是,它不知道哪个处理函数用于哪个异常,因此需要从函数参数的数量中推导出该信息。这意味着程序员仍然有责任为每个异常使用正确的函数类型。幸运的是,x86_64crate定义的InterruptDescriptorTable类型确保使用正确的函数类型。 - 对齐堆栈:有一些指令(特别是SSE指令)需要16字节堆栈对齐。每当发生异常时,CPU都会确保这种对齐,但是对于某些异常,它会在将错误代码压入堆栈时再次破坏它。 x86中断调用约定通过在这种情况下重新排列堆栈来处理这个问题。
如果您对更多细节感兴趣:我们还有一系列帖子解释了如何使用裸函数处理异常,见本文末尾。
实现
现在我们已经理解了这些个理论,现在是时候在我们的内核中处理CPU异常了。我们首先在 src/interrupts.rs中创建一个新的中断模块,首先创建一个init_idt函数,创建一个新的InterruptDescriptorTable:
1 | // in src/lib.rs |
现在我们可以添加处理函数了。 我们首先为断点异常添加一个处理程序。 断点异常是测试异常处理的完美异常。 它的唯一目的是在执行断点指令int3时暂时暂停程序。
断点异常通常用在调试器中:当用户设置断点时,调试器会使用int3指令覆盖相应的指令,以便CPU在到达该行时抛出断点异常。 当用户想要继续该程序时,调试器再次用原始指令替换int3指令并继续该程序。 有关更多详细信息,请参阅“调试器如何工作”系列。
对于我们的用例,我们不需要覆盖任何指令。 相反,我们只想在执行断点指令时打印一条消息,然后继续该程序。 那么让我们创建一个简单的breakpoint_handler函数并将其添加到我们的IDT中:
1 | // in src/interrupts.rs |
我们的处理程序只输出一条消息并打印异常堆栈帧。
当我们尝试编译它时,会发生以下错误:
1 | When we try to compile it, the following error occurs: |
发生此错误是因为x86中断调用约定仍然不稳定。 现在无论如何也要使用它,我们必须通过在我们的lib.rs顶部添加#![feature(abi_x86_interrupt)]来显式启用它。
加载IDT
为了使用我们新的中断描述符表,我们需要使用lidt指令加载它。 x86_64的InterruptDescriptorTable结构为它提供了一个load函数。 我们试着用用它:
1 | // in src/interrupts.rs |
当我们尝试编译它时,会发生以下错误:
1 | error: `idt` does not live long enough |
看来load方法需要一个 &'static self,这是一个在程序的整个运行过程中都有效的引用。原因是CPU将在每次中断时访问此表,直到我们加载不同的IDT。因此,使用比'static更短的生命周期可能导致免费使用后的错误。
事实上,这正是这里发生的事情。我们的idt是在堆栈上创建的,所以它只在init函数中有效。之后堆栈被其他函数使用了,因此CPU会将不知道是啥的堆栈空间解释为IDT。幸运的是,InterruptDescriptorTable::load方法在其函数定义中对此生命周期要求进行编码,以便Rust编译器能够在编译时防止这种可能的错误。
为了解决这个问题,我们需要将idt存储在具有'static生命周期的地方。为了实现这一点,我们可以使用Box在堆上分配IDT,然后将其转换为'static引用,但我们正在编写OS内核,因此没有堆(暂时)。
作为替代方案,我们可以尝试将IDT存储为static:
1 | static IDT: InterruptDescriptorTable = InterruptDescriptorTable::new(); |
但是,有一个问题:static是不可变的,所以我们不能修改init函数的断点条目。 我们可以通过使用static mut来解决这个问题:
1 | static mut IDT: InterruptDescriptorTable = InterruptDescriptorTable::new(); |
编译没有错误,但它并非惯用方法。 static mut非常容易出现数据争用,因此我们需要在每次访问时使用unsafe块。
Lazy Statics 前来支援
幸运的是,有lazy_static宏存在。 宏在第一次引用static变量时执行初始化,而不是在编译时评估静态。 因此,我们几乎可以在初始化块中执行所有操作,甚至可以读取运行时值。
当我们为VGA文本缓冲区创建抽象时,我们已经导入了lazy_static包。 所以我们可以直接使用 lazy_static! 宏来创建我们的静态IDT:
1 | // in src/interrupts.rs |
请注意此解决方案不需要unsafe块。 lazy_static! 宏确实在幕后使用unsafe,但它抽象出了一个安全的用户接口。
测试一下
现在我们应该能够处理断点异常了! 我们在_start函数中尝试一下:
1 | // in src/main.rs |
当我们用QEMU运行这个(用bootimage run),我们会得到:
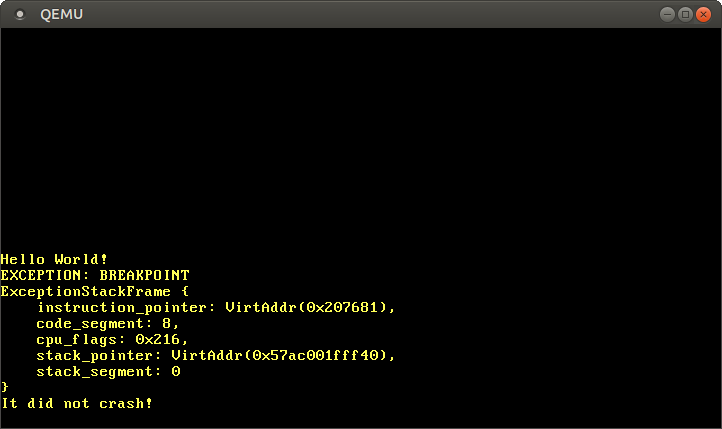
有用! CPU成功调用我们的断点处理程序,它打印消息,然后返回到_start函数,它没有崩溃! 信息已成功打印。
我们看到异常堆栈帧告诉我们异常发生时的指令和堆栈指针。 调试意外异常时,此信息非常有用。
添加测试
让我们创建一个集成测试,确保上述内容继续有效。 为此,我们创建了一个名为test-exception-breakpoint.rs的文件:
1 | // in src/bin/test-exception-breakpoint.rs |
它与我们的主要类似,但不是打印“它没有崩溃!”到VGA缓冲区,它向串行输出打印“ok”并调用exit_qemu。这允许bootimage工具在调用int3指令后检测到我们的代码成功继续。如果我们的panic_handler被调用,我们改为打印失败,表示无法启动bootimage。
您可以通过运行bootimage test来尝试这个新测试。
在Windows[^1]上修复cargo test
x86中断调用约定有一个恼人的问题:在使用Windows目标的x86中断调用约定编译函数时,LLVM中存在导致“”LLVM ERROR: offset is not a multiple of 16”的错误。通常这没问题,因为我们只编译自定义的x86_64-blog_os.json目标。但是cargo test会为主机系统编译我们的箱子,因此如果主机系统是Windows,则会发生错误。
要解决此问题,我们添加条件编译属性,以便在Windows系统上不编译x86中断函数。我们没有依赖中断模块的任何单元测试,所以我们可以简单地跳过整个模块的编译:
1 | // in src/interrupts.rs |
#之后的!表示这是一个内部属性,并且适用于我们所处的模块。没有!,它只会应用于文件中的下一个项目。 请注意,内部属性必须位于模块的开头。
我们可以通过在lib.rs中使用外部属性(没有!)来实现相同的效果:
1 | // in src/lib.rs |
两种方法都具有完全相同的效果,因此可使用哪个取决于个人偏好。在这种情况下,我更喜欢内部属性,因为它不会使我们的lib.rs和LLVM错误的解决方法混在一起,但无论哪种方式都可以。
魔法太多了?
x86-interrupt 调用约定和InterruptDescriptorTable类型使得异常处理过程相对简单且无痛。如果这对你来说太神奇了,你想学习异常处理的所有细节,我们就会介绍:我们的“处理异常与裸函数”系列展示了如何在没有x86中断调用约定的情况下处理异常并创建它自己的IDT类型。从历史上看,这些帖子是x86中断调用约定和x86_64 crate存在之前的主要异常处理帖子。请注意,这些帖子基于此博客的第一版,可能已过期。
下一步是什么?
我们成功地捕获了我们的第一个异常并从中返回!下一步是确保我们捕获所有异常,因为未捕获的异常会导致致命的三重故障,从而导致系统重置。下一篇文章解释了如何通过正确捕获双重故障来避免这种情况。
[^1]: 别用Windows开发了! 